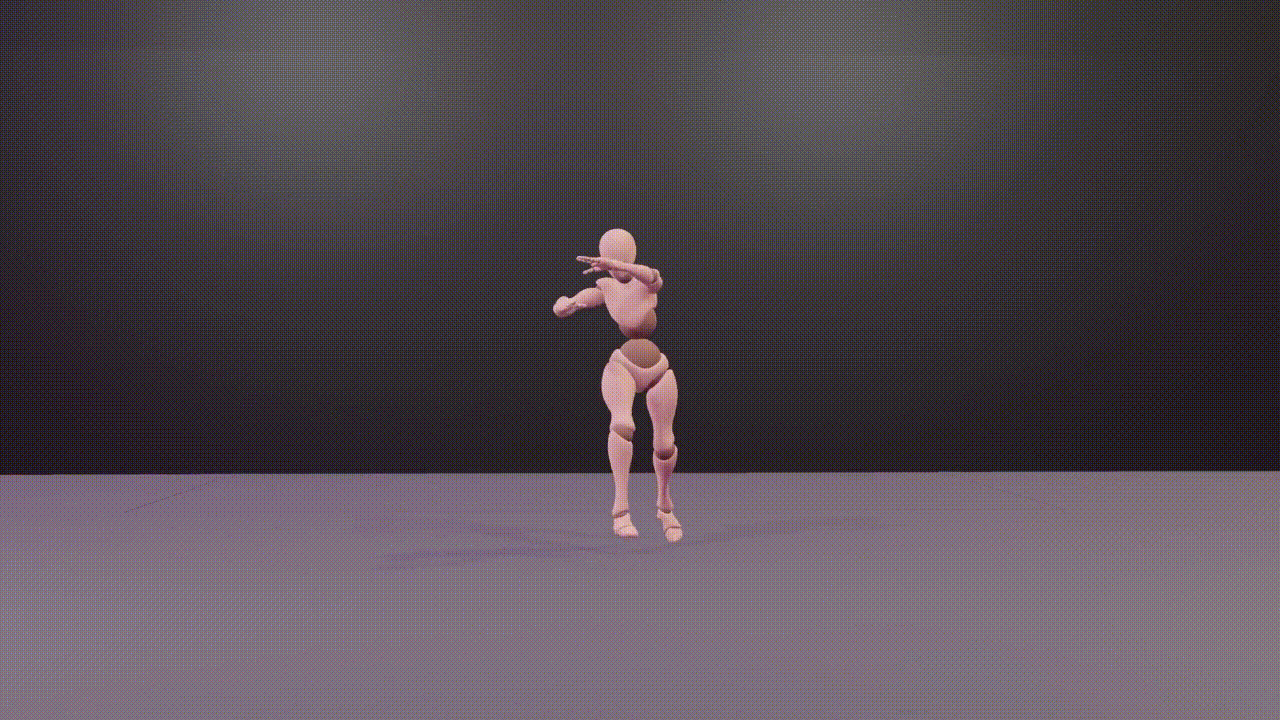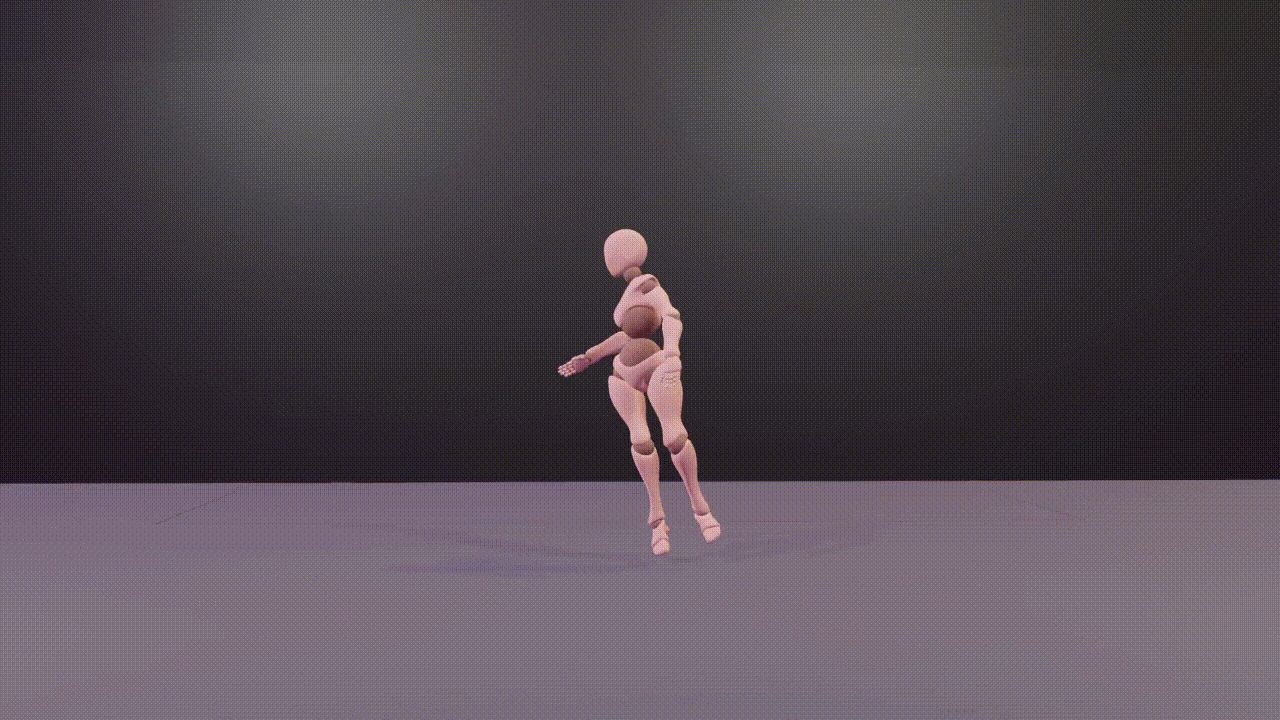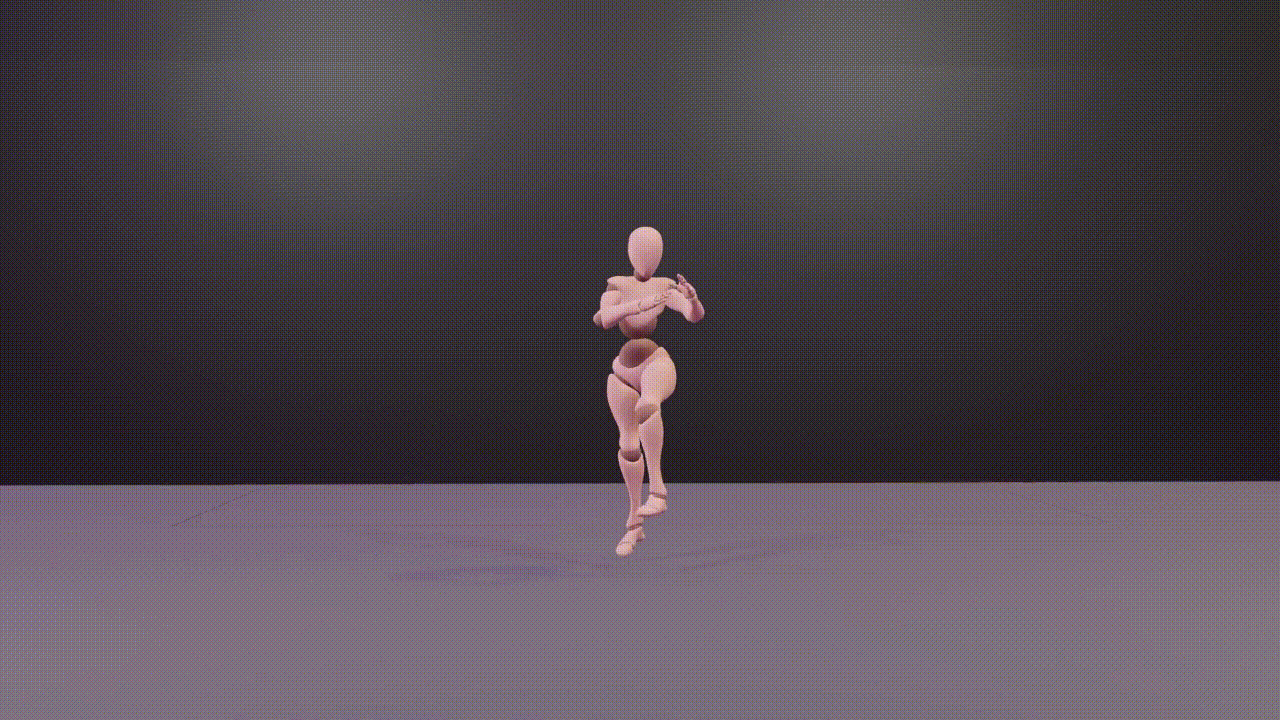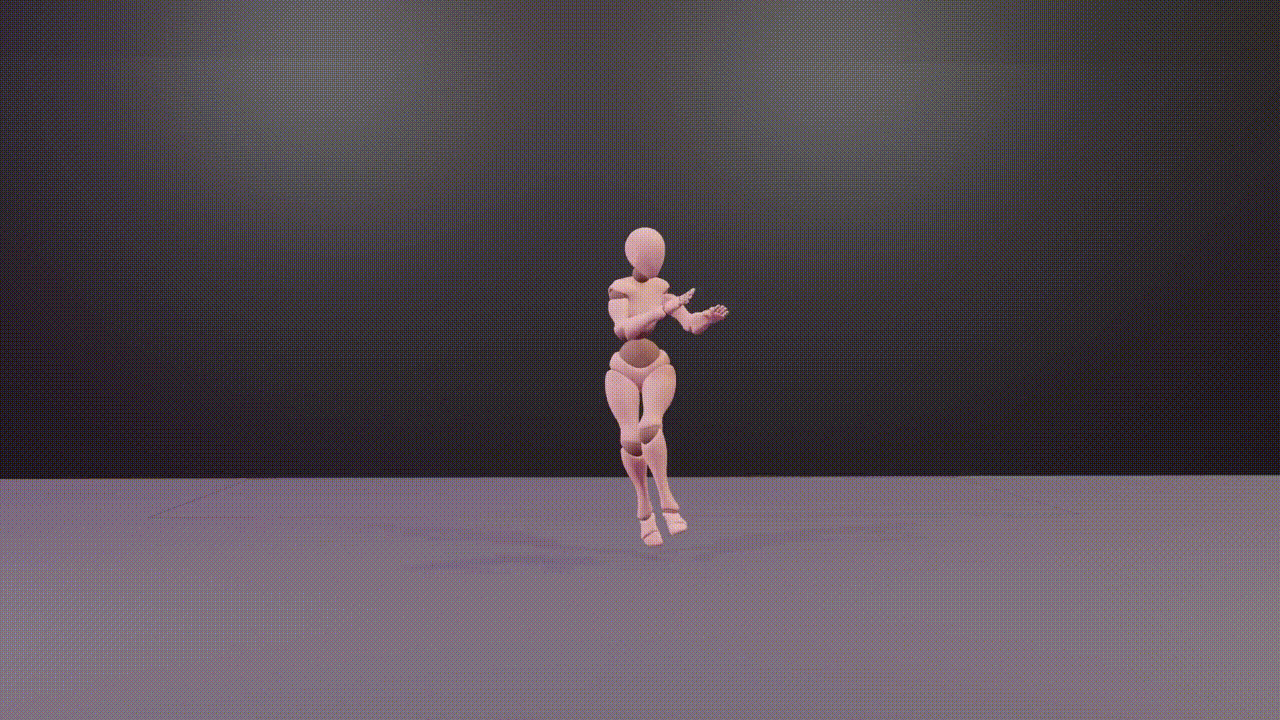@inproceedings{DBLP:conf/aaai/WangZLZZCYT024,author={Wang, Zilin and Zhuang, Haolin and Li, Lu and Zhang, Yinmin and Zhong, Junjie and Chen, Jun and Yang, Yu and Tang, Boshi and Wu, Zhiyong},title={Explore 3D Dance Generation via Reward Model from Automatically-Ranked Demonstrations},booktitle={Thirty-Eighth {AAAI} Conference on Artificial Intelligence, {AAAI} 2024, February 20-27, 2024, Vancouver, Canada},pages={301--309},publisher={{AAAI} Press},year={2024},webpage={https://sites.google.com/view/e3d2},}
Normalization Enhances Generalization in Visual Reinforcement Learning
Lu Li, Jiafei Lyu, Guozheng Ma, Zilin Wang, Zhenjie Yang, and 2 more authors
In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand, 2024
Recent advances in visual reinforcement learning (RL) have led to impressive success in handling complex tasks. However, these methods have demonstrated limited generalization capability to visual disturbances, which poses a significant challenge to their real-world application and adaptability. Though normalization techniques have demonstrated huge success in supervised and unsupervised learning, their applications in visual RL are still scarce. In this paper, we explore the potential benefits of integrating normalization into visual RL methods with respect to generalization performance. We find that, perhaps surprisingly, incorporating suitable normalization techniques is sufficient to enhance the generalization capabilities, without any additional special design. We utilize the combination of two normalization techniques, CrossNorm and SelfNorm, for generalizable visual RL. Extensive experiments are conducted on DMControl Generalization Benchmark, CARLA, and ProcGen Benchmark to validate the effectiveness of our method. We show that our method significantly improves generalization capability while only marginally affecting sample efficiency. In particular, when integrated with DrQ-v2, our method enhances the test performance of DrQ-v2 on CARLA across various scenarios, from 14% of the training performance to 97%. Our project page: https://sites.google.com/view/norm-generalization-vrl/home
@inproceedings{10.5555/3635637.3662970,author={Li, Lu and Lyu, Jiafei and Ma, Guozheng and Wang, Zilin and Yang, Zhenjie and Li, Xiu and Li, Zhiheng},title={Normalization Enhances Generalization in Visual Reinforcement Learning},year={2024},publisher={International Foundation for Autonomous Agents and Multiagent Systems},booktitle={Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems},pages={1137-1146},numpages={10},keywords={generalization, normalization, visual reinforcement learning},location={Auckland, New Zealand},}
2023
Learning Better with Less: Effective Augmentation for Sample-Efficient Visual Reinforcement Learning
Guozheng Ma, Linrui Zhang, Haoyu Wang, Lu Li, Zilin Wang, and 4 more authors
In Advances in Neural Information Processing Systems, 2023
Data augmentation (DA) is a crucial technique for enhancing the sample efficiency of visual reinforcement learning (RL) algorithms.Notably, employing simple observation transformations alone can yield outstanding performance without extra auxiliary representation tasks or pre-trained encoders. However, it remains unclear which attributes of DA account for its effectiveness in achieving sample-efficient visual RL. To investigate this issue and further explore the potential of DA, this work conducts comprehensive experiments to assess the impact of DA’s attributes on its efficacy and provides the following insights and improvements: (1) For individual DA operations, we reveal that both ample spatial diversity and slight hardness are indispensable. Building on this finding, we introduce Random PadResize (Rand PR), a new DA operation that offers abundant spatial diversity with minimal hardness. (2) For multi-type DA fusion schemes, the increased DA hardness and unstable data distribution result in the current fusion schemes being unable to achieve higher sample efficiency than their corresponding individual operations. Taking the non-stationary nature of RL into account, we propose a RL-tailored multi-type DA fusion scheme called Cycling Augmentation (CycAug), which performs periodic cycles of different DA operations to increase type diversity while maintaining data distribution consistency. Extensive evaluations on the DeepMind Control suite and CARLA driving simulator demonstrate that our methods achieve superior sample efficiency compared with the prior state-of-the-art methods.
@inproceedings{DBLP:conf/nips/MaZWLWWSWT23,author={Ma, Guozheng and Zhang, Linrui and Wang, Haoyu and Li, Lu and Wang, Zilin and Wang, Zhen and Shen, Li and Wang, Xueqian and Tao, Dacheng},booktitle={Advances in Neural Information Processing Systems},pages={59832--59859},publisher={Curran Associates, Inc.},title={Learning Better with Less: Effective Augmentation for Sample-Efficient Visual Reinforcement Learning},volume={36},year={2023},}
UnifiedGesture: A Unified Gesture Synthesis Model for Multiple Skeletons
Sicheng Yang*, Zilin Wang*, Zhiyong Wu, Minglei Li, Zhensong Zhang, and 6 more authors
@inproceedings{DBLP:conf/mm/YangW00ZHHXWYD23,author={Yang, Sicheng and Wang, Zilin and Wu, Zhiyong and Li, Minglei and Zhang, Zhensong and Huang, Qiaochu and Hao, Lei and Xu, Songcen and Wu, Xiaofei and Yang, Changpeng and Dai, Zonghong},title={UnifiedGesture: A Unified Gesture Synthesis Model for Multiple Skeletons},year={2023},pages={1033-1044},url={https://doi.org/10.1145/3581783.3612503},booktitle={ACM Multimedia},}
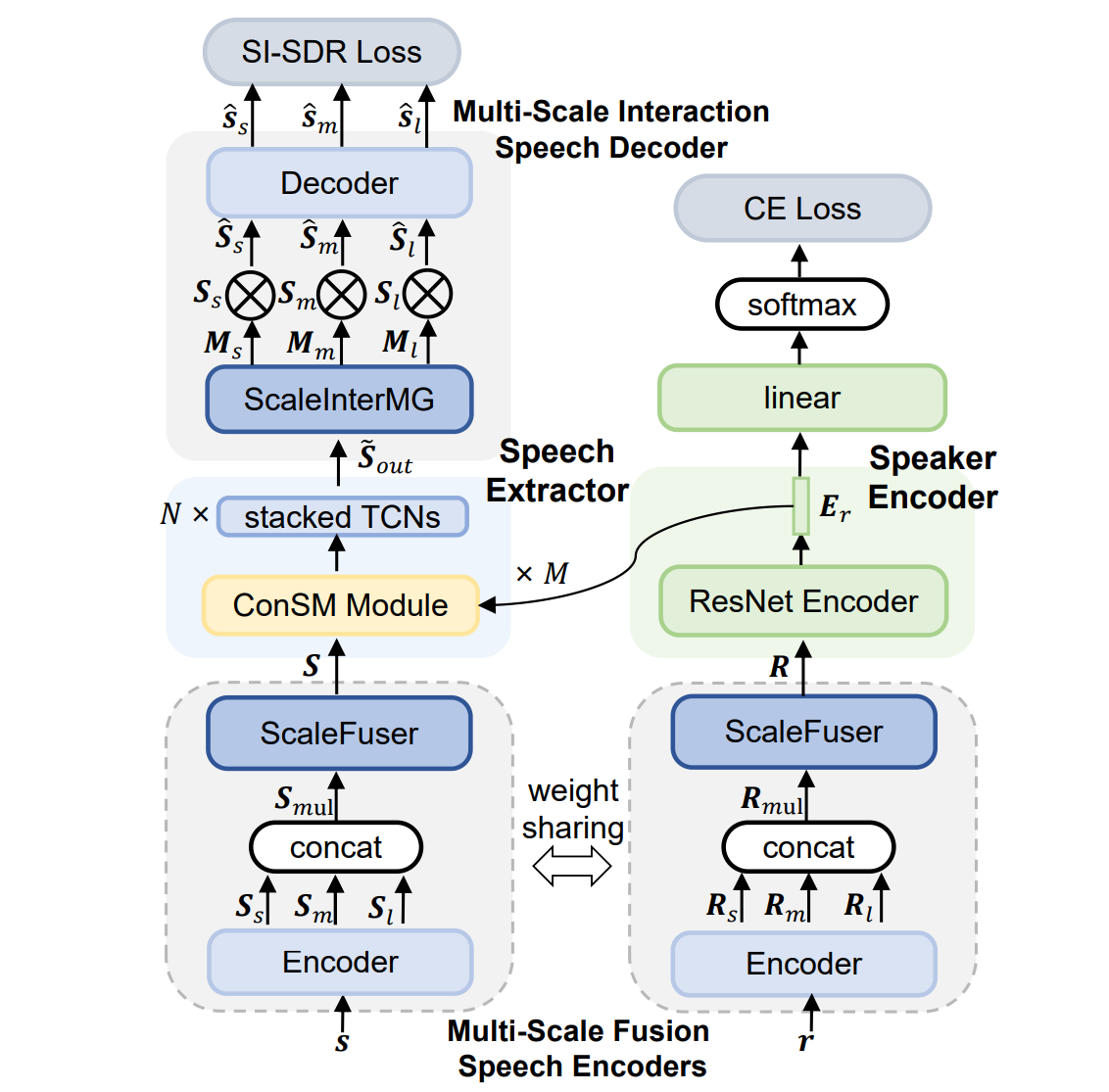
MC-SpEx: Towards Effective Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation
Jun Chen, Wei Rao, Zilin Wang, Jiuxin Lin, Yukai Ju, and 3 more authors
In 24th Annual Conference of the International Speech Communication Association, Interspeech 2023, Dublin, Ireland, August 20-24, 2023, 2023
@inproceedings{DBLP:conf/interspeech/0024RWLJHW023,author={Chen, Jun and Rao, Wei and Wang, Zilin and Lin, Jiuxin and Ju, Yukai and He, Shulin and Wang, Yannan and Wu, Zhiyong},title={MC-SpEx: Towards Effective Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation},booktitle={24th Annual Conference of the International Speech Communication Association, Interspeech 2023, Dublin, Ireland, August 20-24, 2023},pages={4034--4038},publisher={{ISCA}},year={2023},url={https://doi.org/10.21437/Interspeech.2023-1130},webpage={https://rookiejunchen.github.io/MC-SpEx_demo/},}
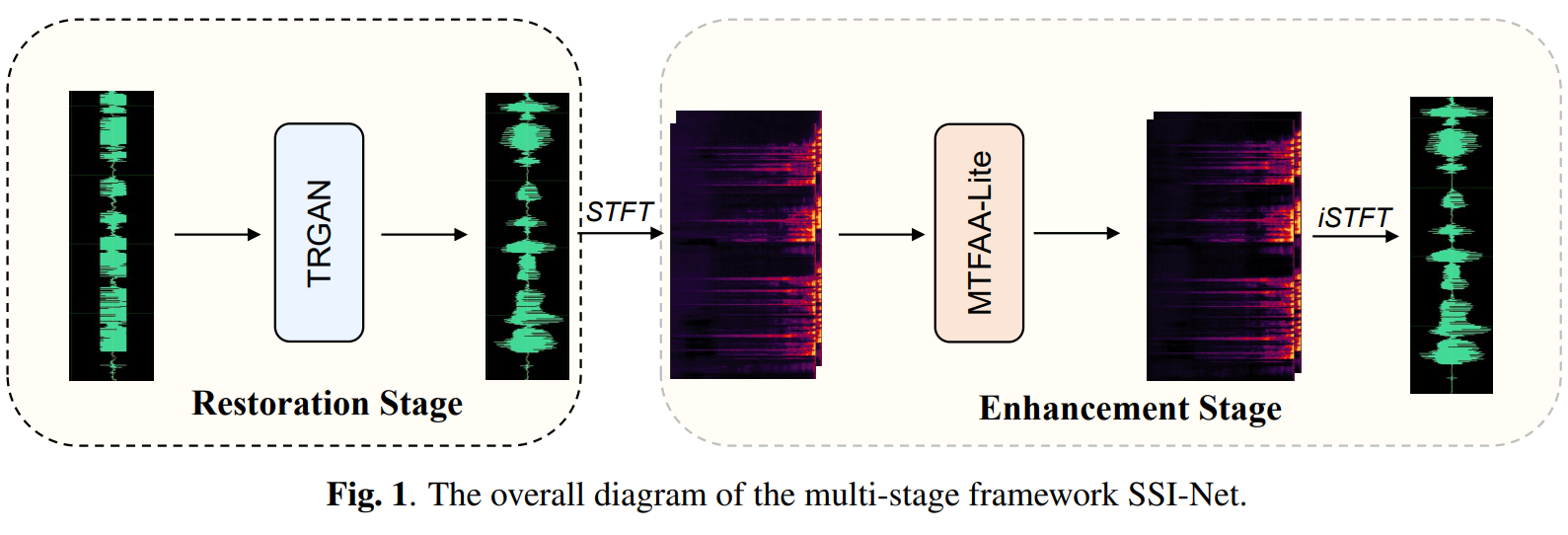
SSI-Net: A Multi-Stage Speech Signal Improvement System for ICASSP 2023 SSI Challenge
Weixin Zhu, Zilin Wang, Jiuxin Lin, Chang Zeng, and Tao Yu
In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
@inproceedings{10094845,author={Zhu, Weixin and Wang, Zilin and Lin, Jiuxin and Zeng, Chang and Yu, Tao},booktitle={ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},title={SSI-Net: A Multi-Stage Speech Signal Improvement System for ICASSP 2023 SSI Challenge},year={2023},pages={1-2},}
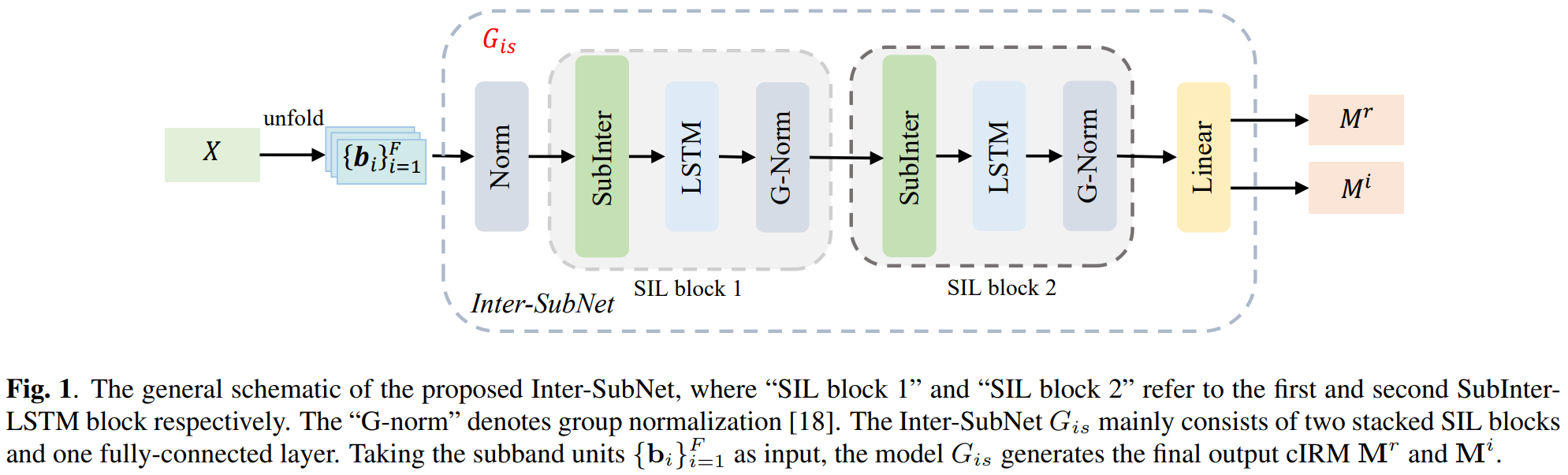
Inter-Subnet: Speech Enhancement with Subband Interaction
Jun Chen, Wei Rao, Zilin Wang, Jiuxin Lin, Zhiyong Wu, and 3 more authors
In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
@inproceedings{10094858,author={Chen, Jun and Rao, Wei and Wang, Zilin and Lin, Jiuxin and Wu, Zhiyong and Wang, Yannan and Shang, Shidong and Meng, Helen},booktitle={ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},title={Inter-Subnet: Speech Enhancement with Subband Interaction},year={2023},pages={1-5},keywords={Noise reduction;Speech enhancement;Signal processing;Acoustics;subband interaction;global spectral information;Inter-SubNet;speech enhancement},webpage={https://rookiejunchen.github.io/Inter-SubNet_demo/},}
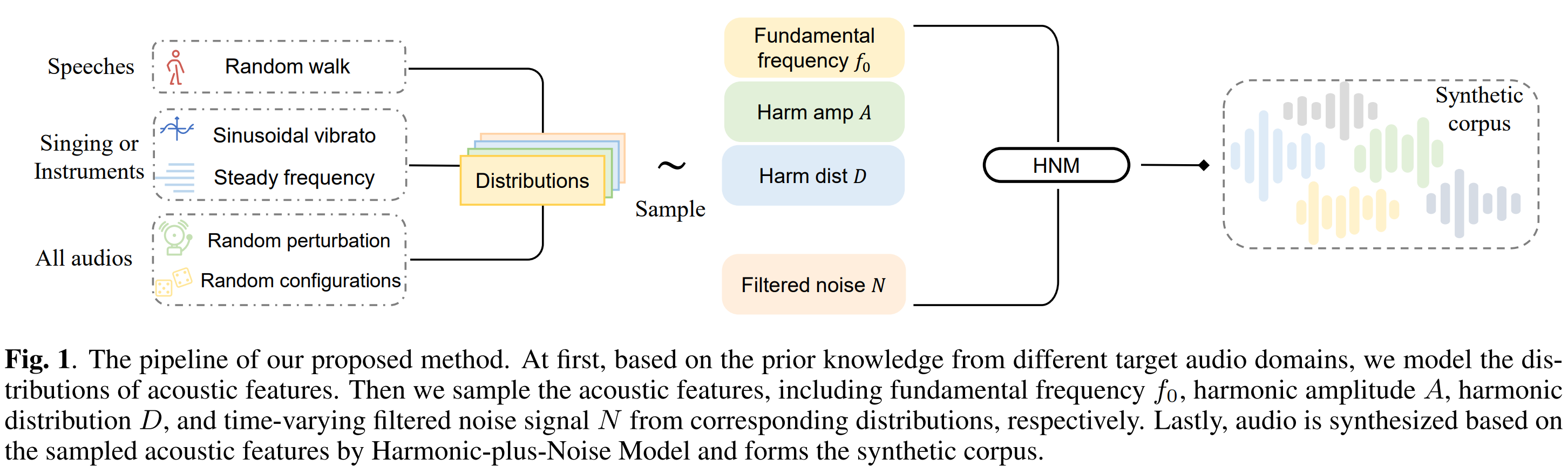
A Synthetic Corpus Generation Method for Neural Vocoder Training
Zilin Wang, Peng Liu, Jun Chen, Sipan Li, Jinfeng Bai, and 3 more authors
In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
@inproceedings{10094786,author={Wang, Zilin and Liu, Peng and Chen, Jun and Li, Sipan and Bai, Jinfeng and He, Gang and Wu, Zhiyong and Meng, Helen},booktitle={ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},title={A Synthetic Corpus Generation Method for Neural Vocoder Training},year={2023},pages={1-5},webpage={https://zerlinwang.github.io/synthetic-corpus-vocoder/},}
2022
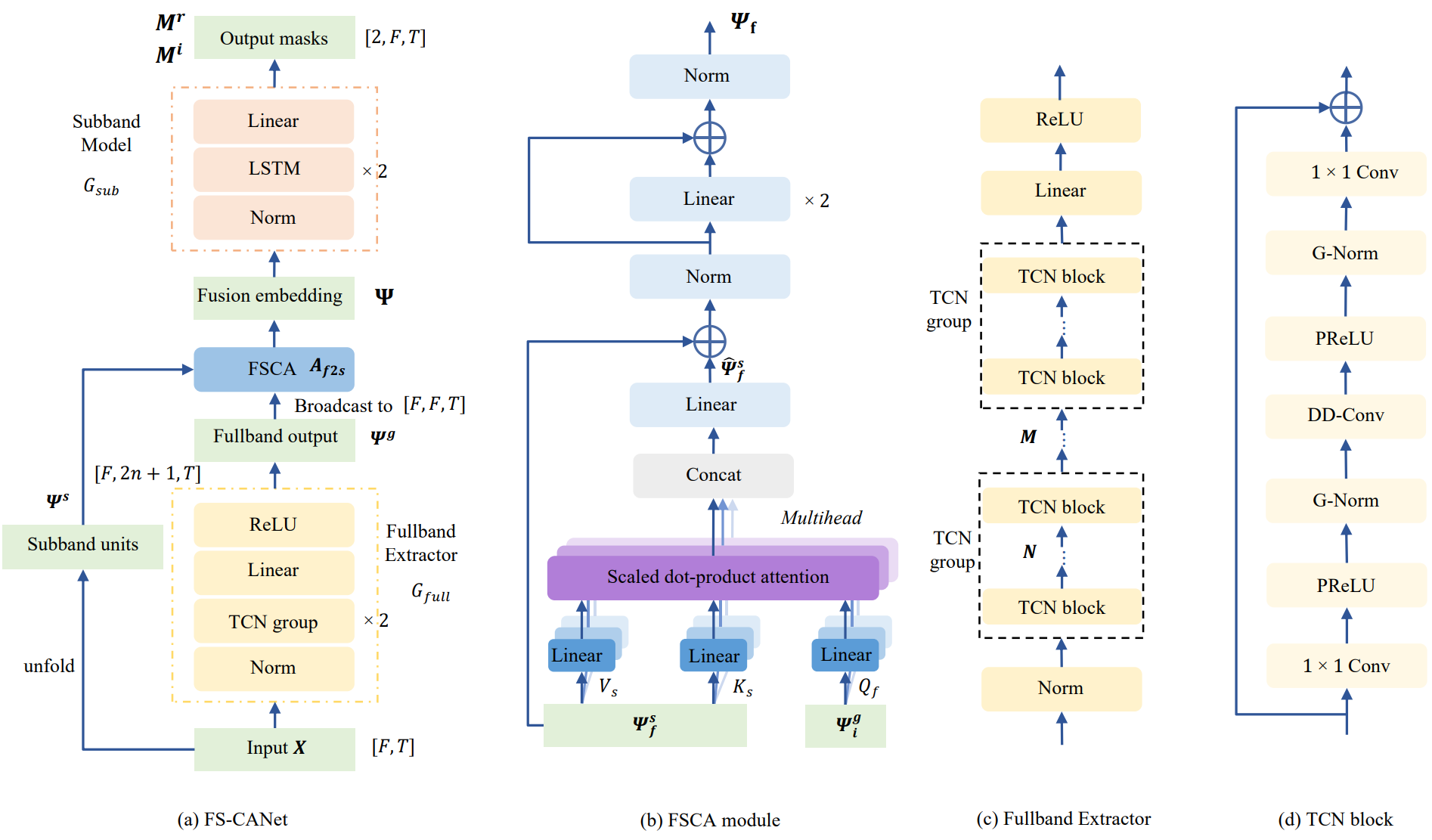
Speech Enhancement with Fullband-Subband Cross-Attention Network
Jun Chen, Wei Rao, Zilin Wang, Zhiyong Wu, Yannan Wang, and 3 more authors
In 23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022, 2022
@inproceedings{DBLP:conf/interspeech/ChenRW0WYSM22,author={Chen, Jun and Rao, Wei and Wang, Zilin and Wu, Zhiyong and Wang, Yannan and Yu, Tao and Shang, Shidong and Meng, Helen},title={Speech Enhancement with Fullband-Subband Cross-Attention Network},booktitle={23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022},pages={976--980},publisher={{ISCA}},year={2022},url={https://doi.org/10.21437/Interspeech.2022-10257},}
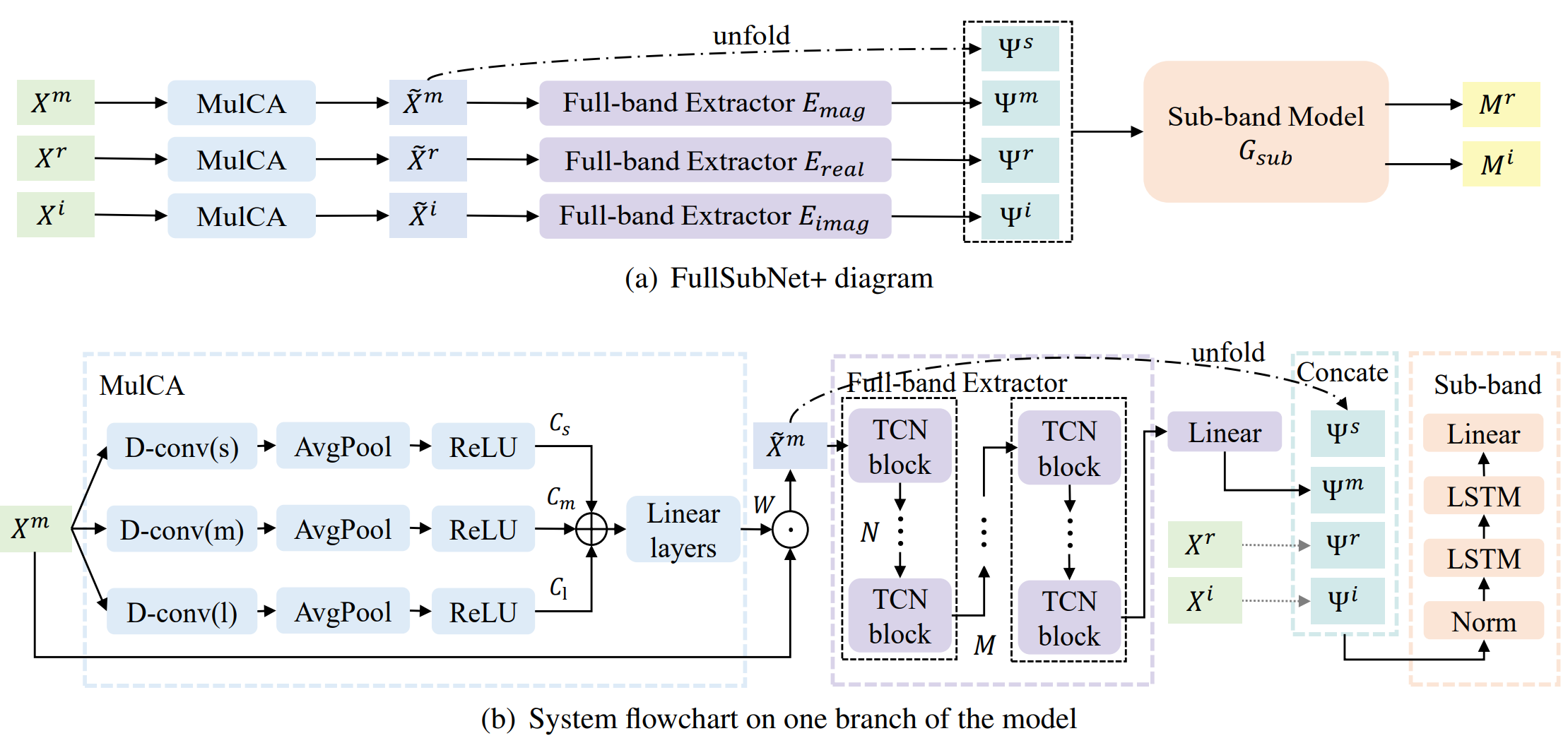
FullSubNet+: Channel Attention Fullsubnet with Complex Spectrograms for Speech Enhancement
Jun Chen, Zilin Wang, Deyi Tuo, Zhiyong Wu, Shiyin Kang, and 1 more author
In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
@inproceedings{9747888,author={Chen, Jun and Wang, Zilin and Tuo, Deyi and Wu, Zhiyong and Kang, Shiyin and Meng, Helen},booktitle={ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},title={FullSubNet+: Channel Attention Fullsubnet with Complex Spectrograms for Speech Enhancement},year={2022},pages={7857-7861},keywords={Time-frequency analysis;Convolution;Conferences;Noise reduction;Memory management;Speech enhancement;Feature extraction;speech enhancement;multi-scale time sensitive channel attention;phase information;full-band extractor},url={https://ieeexplore.ieee.org/document/9747888},webpage={https://rookiejunchen.github.io/fullsubnet-plus.github.io/},}